Assignment 11 - Make-up
Due date: Thursday, December 8th at midnight.
Please notice that late submissions will *NOT* be accepted!
Be sure to use version control ("git"), as you develop your code. Do "git add ...., git commit" repeatedly as you add and edit your code. You will hand in the output of "git log" for your assignment repository as part of the assignment.
1a) Create a file myutils.R which contains a function called word_count, that accepts two arguments, one mandatory and one optional. The function should decompose the mandatory first argument into its component words without punctuation, create a data frame with two columns which contains a row for each word, and the number of times that word appears in the string.
Use the optional second argument of the function to specify the vector of stop words you would like to exclude from the data frame. The function should then return the data frame.
> source("myutils.R")
> word_count("hello there")
word count
1 hello 1
2 there 1
>
> word_count("this is a wonderful wonderful world")
word count
1 this 1
2 is 1
3 a 1
4 wonderful 2
5 world 1
>
> word_count("this is a wonderful wonderful world", stopwords = c("this", "is", "a"))
word count
1 wonderful 2
2 world 1
Note, the string function strsplit used with a regular expression (regex) [^a-zA-Z']+ could be helpful here.
1b) Add another function named read_file to the file myutils.R. This function should receive a file name as the first mandatory argument and an optional flag as the second argument, read the file, convert the text to lower case if the optional flag is TRUE (the built-in function tolower could be useful here), and return its contents. You can use the first three commands in this sequence of commands as an outline of how to read the data from a file.
> my.file <- file("shakespeare.sonnets.txt", "r")
> file.content <- readLines(my.file, warn = FALSE)
> close(my.file)
> file.content[1:5]
[1] ""
[2] ""
[3] " 1"
[4] " From fairest creatures we desire increase,"
[5] " That thereby beauty's rose might never die,"
>
> one.string <- paste(file.content, collapse = "")
>
Note that the file function, like read.csv, is capable of reading URLs. Downloading the file before reading it is not necessary.
1c) Add the following plotting function to your myutils.R script:
plotTopWords <- function(wordcount, n = 10, filename = "word_count.pdf") {
library(ggplot2)
wordcount_sorted <- wordcount[order(-wordcount$count),]
topN <- wordcount_sorted[1:n,]
ggplot(topN, aes(x = count, xend = 0, y = word, yend = word, colour = word)) +
geom_segment() +
geom_point() +
scale_y_discrete(limits = rev(topN$word)) +
scale_x_continuous(expand = expansion(mult = c(0, 0.1))) +
labs(x = "Number of occurrences",
y = "Words") +
theme_minimal() +
theme(panel.grid.major.y = element_blank(), legend.position = "off")
ggsave(filename, height = n/4)
}
2a) Create a driver script called count_words.R and import your functions from myutils.R. Your driver script, count_words.R, should be able to receive and make use of command line arguments. The script should take a file name as an argument, and using functions read_file and word_count count the word occurrences in the file.
Once the word occurrences have been counted, the script should use the provided function plotTopWords to create a plot which displays the results of the word count.
As a test, use the script to count the word frequencies in the file shakespeare.sonnets.txt (link: https://pages.scinet.utoronto.ca/~afedosee/shakespeare.sonnets.txt). Your output should look like the bar plot below.
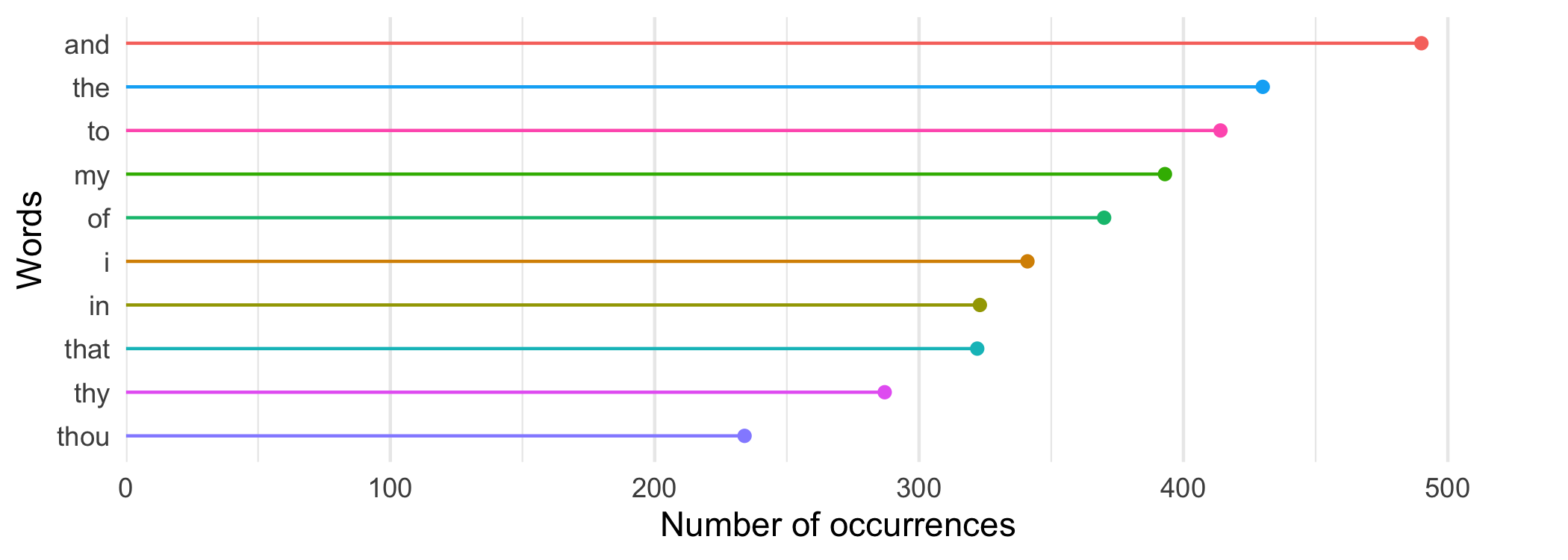
You should not hard code the file names in your script. Use command line arguments to pass the file name into the script.
2b) Download the file stopwords_en.txt (link: https://pages.scinet.utoronto.ca/~afedosee/stopwords_en.txt) containing several stop words.
Modify your driver script so that it will now take an optional argument. This optional second argument is a file of stop words. If the optional stop-words-file argument is supplied, the script should run the function "word_count" using the stop words taken from the stop words file.
Use the stop words from the provided file stopwords_en.txt (use the read_file to read the stop words) to test your script.
If the stop words file is supplied the script should still plot the results using the provided function plotTopWords.
3) Create a bash script named compare_words.sh that runs your script count_words.R twice:
- Once on the
shakespeare.sonnets.txtfile without using stop words and - Once on the
shakespeare.sonnets.txtfile using thestopwords_en.txtstop words file.
Note: do not use any specialty R packages to perform the counting of the words. Write your own!
Please submit your utilities file, driver script and bash script, and the output of 'git log' for this assignment. As usual, the scripts should be well documented, explaining the logic of each step; we will take points off for poorly-commented code. Be sure to use defensive programming for your command line arguments.
To capture the output of 'git log' use redirection, git log > git.log, and hand in the git.log file.
Assignments will be graded on a 10 point basis.
Due date is December 8, 2022 at 11:55pm. Please notice that late submissions will *NOT* be accepted!.